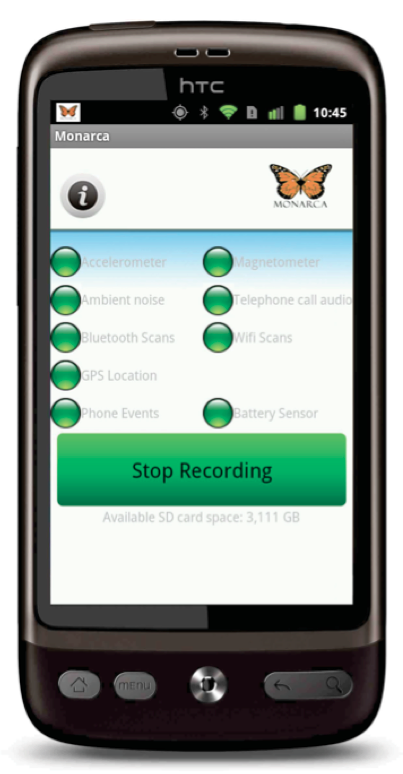
A comprehensive, production-ready Python client library for Milvus vector database operations
Designed for AI and machine learning applications requiring high-performance vector operations
Features
Core Capabilities
- Async/Await Support – High-performance asynchronous operations
- ️ Comprehensive Vector Operations – Full CRUD operations with advanced querying
- Enterprise Security – Built-in authentication, encryption, and access control
- ☁️ Multi-Cloud Storage – AWS S3, Google Cloud Storage, Azure Blob integration
- Real-time Streaming – Kafka integration for live data processing
- Monitoring & Metrics – Prometheus integration with custom metrics
- Multi-modal Support – Text, image, audio, and custom embeddings
- ⚡ Batch Processing – Optimized for large-scale operations
- ️ Robust Error Handling – Automatic retries and graceful degradation
Advanced Features
- Intelligent Indexing – Support for IVF, HNSW, ANNOY, and custom indexes
- Distributed Processing – Horizontal scaling and load balancing
- Smart Caching – Redis integration for performance optimization
- Data Synchronization – Cross-service data consistency
- Backup & Recovery – Automated disaster recovery procedures
- ️ Configuration Management – Environment-based configuration
- Comprehensive Logging – Structured logging with multiple outputs
Installation
Requirements
- Python 3.9 or higher
- Milvus 2.3.0 or higher
Install from PyPI
pip install ai-prishtina-milvus-client
Install from Source
git clone https://github.com/ai-prishtina/milvus-client.git
cd milvus-client
pip install -e .
Development Installation
git clone https://github.com/ai-prishtina/milvus-client.git
cd milvus-client
pip install -e ".[dev]"
⚡ Quick Start
Basic Usage
import asyncio
import numpy as np
from ai_prishtina_milvus_client import AsyncMilvusClient
async def main():
# Initialize client with configuration
config = {
"host": "localhost",
"port": 19530,
"secure": False,
"timeout": 30
}
client = AsyncMilvusClient(config)
try:
# Connect to Milvus
await client.connect()
print("✅ Connected to Milvus")
# Create a collection for image embeddings
collection_name = "image_embeddings"
await client.create_collection(
collection_name=collection_name,
dimension=512, # Common for image embeddings
index_type="HNSW",
metric_type="COSINE",
description="Image embeddings collection"
)
print(f"✅ Created collection: {collection_name}")
# Generate sample embeddings
num_vectors = 1000
vectors = np.random.rand(num_vectors, 512).tolist()
metadata = [
{
"image_id": f"img_{i:06d}",
"category": np.random.choice(["person", "animal", "object"]),
"confidence": np.random.uniform(0.8, 1.0),
"timestamp": "2024-01-01T00:00:00Z"
}
for i in range(num_vectors)
]
# Insert vectors with metadata
ids = await client.insert(
collection_name=collection_name,
vectors=vectors,
metadata=metadata
)
print(f"✅ Inserted {len(ids)} vectors")
# Wait for indexing to complete
await asyncio.sleep(2)
# Perform similarity search
query_vector = np.random.rand(512).tolist()
results = await client.search(
collection_name=collection_name,
query_vectors=[query_vector],
top_k=5,
search_params={"ef": 64} # HNSW parameter
)
print(f" Found {len(results[0])} similar images:")
for i, result in enumerate(results[0]):
metadata = result.get("metadata", {})
print(f" {i+1}. ID: {result['id']}, "
f"Distance: {result['distance']:.4f}, "
f"Category: {metadata.get('category', 'unknown')}")
finally:
await client.disconnect()
print("✅ Disconnected from Milvus")
if __name__ == "__main__":
asyncio.run(main())
Comprehensive Examples
1. Text Embeddings with Transformers
import asyncio
from sentence_transformers import SentenceTransformer
from ai_prishtina_milvus_client import AsyncMilvusClient
async def text_similarity_example():
"""Example: Text similarity search using sentence transformers."""
# Initialize sentence transformer
model = SentenceTransformer('all-MiniLM-L6-v2')
# Sample documents
documents = [
"The quick brown fox jumps over the lazy dog",
"Machine learning is a subset of artificial intelligence",
"Python is a popular programming language for data science",
"Vector databases enable efficient similarity search",
"Natural language processing helps computers understand text"
]
# Generate embeddings
embeddings = model.encode(documents).tolist()
# Initialize Milvus client
client = AsyncMilvusClient({
"host": "localhost",
"port": 19530
})
try:
await client.connect()
# Create collection for text embeddings
collection_name = "text_embeddings"
await client.create_collection(
collection_name=collection_name,
dimension=384, # all-MiniLM-L6-v2 dimension
index_type="IVF_FLAT",
metric_type="COSINE"
)
# Insert documents with embeddings
metadata = [
{
"text": doc,
"length": len(doc),
"word_count": len(doc.split())
}
for doc in documents
]
ids = await client.insert(
collection_name=collection_name,
vectors=embeddings,
metadata=metadata
)
# Search for similar documents
query = "What is machine learning?"
query_embedding = model.encode([query]).tolist()
results = await client.search(
collection_name=collection_name,
query_vectors=query_embedding,
top_k=3,
output_fields=["text", "word_count"]
)
print(f"Query: {query}")
print("Similar documents:")
for result in results[0]:
print(f" - {result['metadata']['text']}")
print(f" Similarity: {1 - result['distance']:.4f}")
finally:
await client.disconnect()
asyncio.run(text_similarity_example())
2. Batch Processing with Progress Tracking
import asyncio
import numpy as np
from typing import List, Dict, Any
from ai_prishtina_milvus_client import AsyncMilvusClient
async def batch_processing_example():
"""Example: Large-scale batch processing with progress tracking."""
client = AsyncMilvusClient({
"host": "localhost",
"port": 19530
})
try:
await client.connect()
# Create collection for large dataset
collection_name = "large_dataset"
await client.create_collection(
collection_name=collection_name,
dimension=256,
index_type="IVF_SQ8",
metric_type="L2"
)
# Process data in batches
total_vectors = 100000
batch_size = 1000
print(f"Processing {total_vectors} vectors in batches of {batch_size}")
for batch_idx in range(0, total_vectors, batch_size):
end_idx = min(batch_idx + batch_size, total_vectors)
current_batch_size = end_idx - batch_idx
# Generate batch data
vectors = np.random.rand(current_batch_size, 256).tolist()
metadata = [
{
"batch_id": batch_idx // batch_size,
"item_id": batch_idx + i,
"category": f"cat_{(batch_idx + i) % 10}",
"score": np.random.uniform(0, 1)
}
for i in range(current_batch_size)
]
# Insert batch
ids = await client.insert(
collection_name=collection_name,
vectors=vectors,
metadata=metadata
)
# Progress tracking
progress = (end_idx / total_vectors) * 100
print(f"Progress: {progress:.1f}% - Inserted batch {batch_idx//batch_size + 1}")
# Optional: Add delay to prevent overwhelming the system
await asyncio.sleep(0.1)
print("✅ Batch processing completed")
# Verify total count
count = await client.count(collection_name)
print(f"Total vectors in collection: {count}")
finally:
await client.disconnect()
asyncio.run(batch_processing_example())
3. Multi-modal Search with Metadata Filtering
import asyncio
import numpy as np
from ai_prishtina_milvus_client import AsyncMilvusClient
async def multimodal_search_example():
"""Example: Multi-modal search with complex metadata filtering."""
client = AsyncMilvusClient({
"host": "localhost",
"port": 19530
})
try:
await client.connect()
# Create collection for multi-modal data
collection_name = "multimodal_content"
await client.create_collection(
collection_name=collection_name,
dimension=768, # Common for multi-modal embeddings
index_type="HNSW",
metric_type="COSINE"
)
# Insert multi-modal content
content_types = ["text", "image", "audio", "video"]
categories = ["education", "entertainment", "news", "sports"]
vectors = []
metadata = []
for i in range(1000):
vectors.append(np.random.rand(768).tolist())
metadata.append({
"content_id": f"content_{i:06d}",
"content_type": np.random.choice(content_types),
"category": np.random.choice(categories),
"duration": np.random.randint(10, 3600), # seconds
"quality": np.random.choice(["HD", "4K", "SD"]),
"language": np.random.choice(["en", "es", "fr", "de"]),
"upload_date": f"2024-{np.random.randint(1,13):02d}-{np.random.randint(1,29):02d}",
"views": np.random.randint(100, 1000000),
"rating": np.random.uniform(1.0, 5.0)
})
ids = await client.insert(
collection_name=collection_name,
vectors=vectors,
metadata=metadata
)
# Wait for indexing
await asyncio.sleep(3)
# Complex search with metadata filtering
query_vector = np.random.rand(768).tolist()
# Search for high-quality educational videos in English
results = await client.search(
collection_name=collection_name,
query_vectors=[query_vector],
top_k=10,
filter_expression='content_type == "video" and category == "education" and language == "en" and quality in ["HD", "4K"] and rating > 4.0',
output_fields=["content_id", "content_type", "category", "quality", "rating"]
)
print(" Search Results: High-quality educational videos in English")
for i, result in enumerate(results[0]):
meta = result["metadata"]
print(f" {i+1}. {meta['content_id']} - {meta['quality']} - Rating: {meta['rating']:.2f}")
# Aggregate search - find popular content by category
categories_stats = {}
for category in categories:
cat_results = await client.search(
collection_name=collection_name,
query_vectors=[query_vector],
top_k=100,
filter_expression=f'category == "{category}"',
output_fields=["views", "rating"]
)
if cat_results[0]:
avg_views = np.mean([r["metadata"]["views"] for r in cat_results[0]])
avg_rating = np.mean([r["metadata"]["rating"] for r in cat_results[0]])
categories_stats[category] = {
"avg_views": avg_views,
"avg_rating": avg_rating,
"count": len(cat_results[0])
}
print("\n Category Statistics:")
for category, stats in categories_stats.items():
print(f" {category.title()}: {stats['count']} items, "
f"Avg Views: {stats['avg_views']:.0f}, "
f"Avg Rating: {stats['avg_rating']:.2f}")
finally:
await client.disconnect()
asyncio.run(multimodal_search_example())
4. Real-time Streaming with Kafka Integration
import asyncio
import json
import numpy as np
from ai_prishtina_milvus_client import AsyncMilvusClient
from ai_prishtina_milvus_client.streaming import KafkaStreamProcessor, StreamMessage
async def streaming_example():
"""Example: Real-time vector streaming with Kafka."""
# Configuration
milvus_config = {
"host": "localhost",
"port": 19530
}
kafka_config = {
"bootstrap_servers": ["localhost:9092"],
"topic": "vector_stream",
"group_id": "milvus_consumer"
}
# Initialize stream processor
stream_processor = KafkaStreamProcessor(
milvus_config=milvus_config,
stream_config=kafka_config
)
try:
# Setup collection for streaming data
client = AsyncMilvusClient(milvus_config)
await client.connect()
collection_name = "streaming_vectors"
await client.create_collection(
collection_name=collection_name,
dimension=128,
index_type="IVF_FLAT",
metric_type="L2"
)
# Producer: Send vectors to Kafka
async def produce_vectors():
for i in range(100):
# Simulate real-time data
vector = np.random.rand(128).tolist()
metadata = {
"timestamp": "2024-01-01T00:00:00Z",
"source": "sensor_data",
"device_id": f"device_{i % 10}",
"batch_id": i // 10
}
message = StreamMessage(
vectors=[vector],
metadata=[metadata],
operation="insert",
collection=collection_name
)
await stream_processor.produce_message("vector_stream", message)
print(f" Sent vector {i+1}/100")
# Simulate real-time delay
await asyncio.sleep(0.1)
# Consumer: Process vectors from Kafka
async def consume_vectors():
async for message in stream_processor.consume_messages("vector_stream"):
try:
# Process the stream message
result = await stream_processor.process_message(message)
print(f" Processed {len(result)} vectors")
except Exception as e:
print(f"❌ Error processing message: {e}")
# Run producer and consumer concurrently
await asyncio.gather(
produce_vectors(),
consume_vectors()
)
finally:
await stream_processor.close()
await client.disconnect()
# Note: This example requires Kafka to be running
# asyncio.run(streaming_example())
5. Advanced Security and Monitoring
import asyncio
from ai_prishtina_milvus_client import AsyncMilvusClient
from ai_prishtina_milvus_client.security import SecurityManager
from ai_prishtina_milvus_client.monitoring import MetricsCollector
async def security_monitoring_example():
"""Example: Advanced security and monitoring features."""
# Initialize security manager
security_config = {
"encryption_key": "your-encryption-key",
"enable_rbac": True,
"token_expiry": 3600
}
security_manager = SecurityManager(config=security_config)
# Initialize metrics collector
metrics_config = {
"prometheus_gateway": "localhost:9091",
"job_name": "milvus_client",
"enable_system_metrics": True
}
metrics_collector = MetricsCollector(config=metrics_config)
# Initialize client with security and monitoring
client = AsyncMilvusClient({
"host": "localhost",
"port": 19530,
"security_manager": security_manager,
"metrics_collector": metrics_collector
})
try:
# Create user and authenticate
await security_manager.create_user(
username="data_scientist",
password="secure_password",
roles=["read", "write"]
)
auth_token = await security_manager.authenticate(
"data_scientist",
"secure_password"
)
# Connect with authentication
await client.connect(auth_token=auth_token)
# Create collection with encryption
collection_name = "secure_collection"
await client.create_collection(
collection_name=collection_name,
dimension=256,
index_type="HNSW",
metric_type="COSINE",
enable_encryption=True
)
# Insert data with automatic metrics collection
vectors = [np.random.rand(256).tolist() for _ in range(1000)]
metadata = [
{
"user_id": security_manager.encrypt_data(f"user_{i}"),
"sensitive_data": security_manager.encrypt_data(f"data_{i}"),
"public_info": f"info_{i}"
}
for i in range(1000)
]
# Metrics are automatically collected during operations
with metrics_collector.timer("insert_operation"):
ids = await client.insert(
collection_name=collection_name,
vectors=vectors,
metadata=metadata
)
# Search with metrics
query_vector = np.random.rand(256).tolist()
with metrics_collector.timer("search_operation"):
results = await client.search(
collection_name=collection_name,
query_vectors=[query_vector],
top_k=10
)
# Decrypt sensitive data from results
for result in results[0]:
meta = result["metadata"]
if "user_id" in meta:
decrypted_user = security_manager.decrypt_data(meta["user_id"])
print(f"User: {decrypted_user}, Distance: {result['distance']:.4f}")
# Export metrics
await metrics_collector.push_metrics()
# Get performance statistics
stats = metrics_collector.get_stats()
print(f"\n Performance Stats:")
print(f" Insert operations: {stats.get('insert_count', 0)}")
print(f" Search operations: {stats.get('search_count', 0)}")
print(f" Average insert time: {stats.get('avg_insert_time', 0):.3f}s")
print(f" Average search time: {stats.get('avg_search_time', 0):.3f}s")
finally:
await client.disconnect()
asyncio.run(security_monitoring_example())
Configuration
Basic Configuration
from ai_prishtina_milvus_client import AsyncMilvusClient
# Simple configuration
config = {
"host": "localhost",
"port": 19530,
"secure": False,
"timeout": 30
}
client = AsyncMilvusClient(config)
Advanced Configuration
from ai_prishtina_milvus_client import AsyncMilvusClient, MilvusConfig
# Advanced configuration with all options
config = MilvusConfig(
# Connection settings
host="localhost",
port=19530,
secure=True,
timeout=60,
# Authentication
username="admin",
password="password",
token="auth_token",
# Performance settings
pool_size=10,
max_retries=3,
retry_delay=1.0,
# Validation settings
validate_vectors=True,
normalize_vectors=True,
max_vector_dimension=2048,
# Monitoring settings
enable_metrics=True,
metrics_port=8080,
# Logging settings
log_level="INFO",
log_file="milvus_client.log"
)
client = AsyncMilvusClient(config)
Environment Variables
# Set environment variables
export MILVUS_HOST=localhost
export MILVUS_PORT=19530
export MILVUS_USERNAME=admin
export MILVUS_PASSWORD=password
export MILVUS_SECURE=true
export MILVUS_TIMEOUT=60
# Load from environment
from ai_prishtina_milvus_client import AsyncMilvusClient
# Automatically loads from environment variables
client = AsyncMilvusClient.from_env()
API Reference
AsyncMilvusClient
Connection Management
# Connect to Milvus
await client.connect(auth_token=None)
# Disconnect from Milvus
await client.disconnect()
# Check connection status
is_connected = await client.is_connected()
# Get server info
info = await client.get_server_info()
Collection Operations
# Create collection
await client.create_collection(
collection_name: str,
dimension: int,
index_type: str = "IVF_FLAT",
metric_type: str = "L2",
description: str = None,
enable_encryption: bool = False
)
# List collections
collections = await client.list_collections()
# Check if collection exists
exists = await client.has_collection(collection_name)
# Get collection info
info = await client.describe_collection(collection_name)
# Drop collection
await client.drop_collection(collection_name)
# Get collection statistics
stats = await client.get_collection_stats(collection_name)
Vector Operations
# Insert vectors
ids = await client.insert(
collection_name: str,
vectors: List[List[float]],
metadata: List[Dict] = None,
partition_name: str = None
)
# Search vectors
results = await client.search(
collection_name: str,
query_vectors: List[List[float]],
top_k: int = 10,
search_params: Dict = None,
filter_expression: str = None,
output_fields: List[str] = None,
partition_names: List[str] = None
)
# Get vectors by IDs
vectors = await client.get(
collection_name: str,
ids: List[int],
output_fields: List[str] = None
)
# Delete vectors
await client.delete(
collection_name: str,
filter_expression: str
)
# Count vectors
count = await client.count(
collection_name: str,
filter_expression: str = None
)
Index Operations
# Create index
await client.create_index(
collection_name: str,
field_name: str = "vector",
index_params: Dict = None
)
# Drop index
await client.drop_index(
collection_name: str,
field_name: str = "vector"
)
# Get index info
index_info = await client.describe_index(
collection_name: str,
field_name: str = "vector"
)
Partition Operations
# Create partition
await client.create_partition(
collection_name: str,
partition_name: str
)
# List partitions
partitions = await client.list_partitions(collection_name)
# Drop partition
await client.drop_partition(
collection_name: str,
partition_name: str
)
Streaming Operations
from ai_prishtina_milvus_client.streaming import KafkaStreamProcessor
# Initialize stream processor
processor = KafkaStreamProcessor(
milvus_config=milvus_config,
stream_config=kafka_config
)
# Produce message
await processor.produce_message(topic, message)
# Consume messages
async for message in processor.consume_messages(topic):
result = await processor.process_message(message)
Security Operations
from ai_prishtina_milvus_client.security import SecurityManager
# Initialize security manager
security = SecurityManager(config=security_config)
# User management
await security.create_user(username, password, roles)
await security.delete_user(username)
await security.update_user_roles(username, roles)
# Authentication
token = await security.authenticate(username, password)
await security.validate_token(token)
# Data encryption
encrypted = security.encrypt_data(data)
decrypted = security.decrypt_data(encrypted)
Monitoring Operations
from ai_prishtina_milvus_client.monitoring import MetricsCollector
# Initialize metrics collector
metrics = MetricsCollector(config=metrics_config)
# Collect metrics
with metrics.timer("operation_name"):
# Your operation here
pass
# Custom metrics
metrics.increment_counter("custom_counter")
metrics.set_gauge("custom_gauge", value)
metrics.record_histogram("custom_histogram", value)
# Export metrics
await metrics.push_metrics()
stats = metrics.get_stats()
Best Practices
Performance Optimization
# 1. Use batch operations for large datasets
batch_size = 1000
for i in range(0, len(vectors), batch_size):
batch_vectors = vectors[i:i+batch_size]
batch_metadata = metadata[i:i+batch_size]
await client.insert(collection_name, batch_vectors, batch_metadata)
# 2. Choose appropriate index types
# - IVF_FLAT: Good balance of speed and accuracy
# - HNSW: Best for high-accuracy searches
# - IVF_SQ8: Memory-efficient for large datasets
# 3. Use connection pooling for high concurrency
config = {
"pool_size": 20, # Adjust based on your needs
"max_retries": 3
}
# 4. Implement proper error handling
try:
results = await client.search(collection_name, query_vectors, top_k=10)
except MilvusException as e:
logger.error(f"Milvus operation failed: {e}")
# Implement fallback logic
Memory Management
# 1. Process large datasets in chunks
async def process_large_dataset(vectors, chunk_size=10000):
for i in range(0, len(vectors), chunk_size):
chunk = vectors[i:i+chunk_size]
await client.insert(collection_name, chunk)
# Allow garbage collection
del chunk
# 2. Use generators for streaming data
async def vector_generator():
for data in large_dataset:
yield process_data(data)
# 3. Clean up resources
async with AsyncMilvusClient(config) as client:
# Operations here
pass # Automatic cleanup
Security Best Practices
# 1. Use environment variables for sensitive data
import os
config = {
"host": os.getenv("MILVUS_HOST"),
"username": os.getenv("MILVUS_USERNAME"),
"password": os.getenv("MILVUS_PASSWORD")
}
# 2. Enable encryption for sensitive collections
await client.create_collection(
collection_name="sensitive_data",
dimension=768,
enable_encryption=True
)
# 3. Implement proper access control
security_manager = SecurityManager(config={
"enable_rbac": True,
"token_expiry": 3600
})
# 4. Validate input data
from ai_prishtina_milvus_client.validation import VectorValidator
validator = VectorValidator(dimension=768, normalize=True)
validated_vectors = validator.validate(vectors)
Troubleshooting
Common Issues
Connection Problems
# Issue: Connection timeout
# Solution: Increase timeout and check network
config = {
"host": "localhost",
"port": 19530,
"timeout": 60 # Increase timeout
}
# Issue: Authentication failed
# Solution: Check credentials and permissions
try:
await client.connect()
except AuthenticationError:
# Check username/password
# Verify user permissions
Performance Issues
# Issue: Slow search performance
# Solution: Optimize index parameters
index_params = {
"index_type": "HNSW",
"params": {
"M": 16, # Increase for better recall
"efConstruction": 200 # Increase for better quality
}
}
# Issue: High memory usage
# Solution: Use memory-efficient index
index_params = {
"index_type": "IVF_SQ8", # Memory-efficient
"params": {"nlist": 1024}
}
Data Issues
# Issue: Vector dimension mismatch
# Solution: Validate dimensions before insert
if len(vector) != expected_dimension:
raise ValueError(f"Expected dimension {expected_dimension}, got {len(vector)}")
# Issue: Invalid metadata
# Solution: Validate metadata schema
from pydantic import BaseModel
class VectorMetadata(BaseModel):
id: str
category: str
timestamp: str
validated_metadata = [VectorMetadata(**meta) for meta in metadata]
Debugging
# Enable debug logging
import logging
logging.basicConfig(level=logging.DEBUG)
# Use client debugging features
client = AsyncMilvusClient(config, debug=True)
# Monitor operations
from ai_prishtina_milvus_client.monitoring import MetricsCollector
metrics = MetricsCollector(config={"enable_debug": True})
Testing
Unit Tests
# Run unit tests
pytest tests/unit/ -v
# Run with coverage
pytest tests/unit/ --cov=ai_prishtina_milvus_client --cov-report=html
Integration Tests
# Start Docker services
docker-compose up -d
# Run integration tests
pytest tests/integration/ -v
# Run specific test categories
pytest tests/integration/ -m "not slow"
Performance Tests
# Run performance benchmarks
python tests/performance/benchmark.py
# Run load tests
python tests/performance/load_test.py --vectors=100000 --concurrent=10
Documentation
API Documentation
Tutorials
Community
Contributing
We welcome contributions! Please see our Contributing Guide for details.
Development Setup
# Clone repository
git clone https://github.com/ai-prishtina/milvus-client.git
cd milvus-client
# Create virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install development dependencies
pip install -e ".[dev]"
# Install pre-commit hooks
pre-commit install
# Run tests
pytest
Contribution Guidelines
- Follow PEP 8 style guidelines
- Add tests for new features
- Update documentation for API changes
- Use meaningful commit messages
- Create pull requests against the
develop branch
License
This project is dual-licensed:
Open Source License (AGPL-3.0)
For open-source projects, research, and educational use, this software is licensed under the GNU Affero General Public License v3.0 (AGPL-3.0). This means:
- ✅ Free to use for open-source projects
- ✅ Must open-source your entire application if you distribute it
- ✅ Perfect for research and educational purposes
- ✅ Community-driven development
Commercial License
For commercial use, proprietary applications, or when you cannot comply with AGPL-3.0 requirements:
- Commercial applications and SaaS products
- Proprietary software without open-source requirements
- Enterprise support and custom development
- Priority support and SLA guarantees
Need a commercial license? Contact: alban.q.maxhuni@gmail.com
See the LICENSE file for complete details.
Author
Alban Maxhuni, PhD Email: alban.q.maxhuni@gmail.com | info@albanmaxhuni.com
Acknowledgments